Oct 2, 2010: Model Convergence
home faq articles premium contact
Predictive statistical models are "reality simplification" devices.
They never predict the future perfectly, but they can do so in a way that is much more accurate than random chance.
One of the ways I use to evaluate models is by feeding them data they've never seen before, and checking the magnitude of the error. The error is the difference between the prediction and the actual value (which is known after the fact). An ideal, perfect model, makes no errors: its predicted values are exactly equal to the actual values.
Another way to evaluate a model is to peek into its state continuously while it is being built. Imagine iterating over examples one by one, essentially by replaying some past period without peeking forward. This process is called "online learning". During this online learning process we continuously look at the magnitude of the error that the (partial) model makes. If there's any consistent statistical relationship between past and future, then the model should "learn" and improve over time.
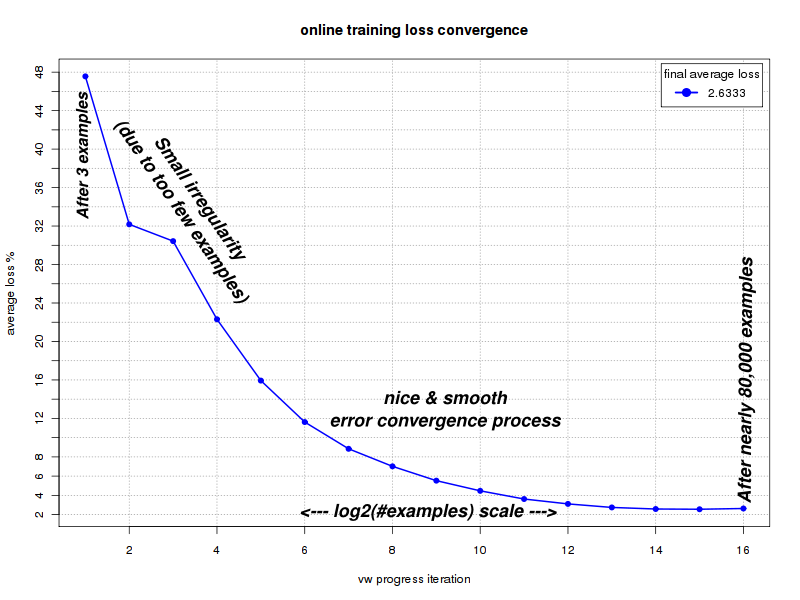
In other words: if during the learning phase, the model converges on a smaller and smaller mean-error (which is often called 'loss' by Machine Learning practitioners), it means that:
- There is a "signal" (statistical relation) between the input (past) and the output (future). The model wouldn't converge (i.e. reduce its error) when fed with random data.
- The relation has some (statistical) consistency which allows it to learn more and more as more examples are added to the training data set.
- The model is becoming better as the training-set gets bigger
- There's a limit beyond which we cannot go. In essence every "real life" model eventually learns everything that can be learned from a certain set of examples, using a certain method, and can improve no further. From the point where the noise wins over the signal, no further learning (error reduction) can happen.
In the image above we see such a process of error convergence of one of my models. Every unit on the X-axis indicates doubling the number of examples (the X-scale is approximately a log2() scale). Obviously there's a lot of noise in the data and we cannot expect each and every single example to improve the error. This is why the chart is not very smooth at the beginning where the number of examples is very small. What we do expect, is a reduction of the error as we double the number of examples. In this particular experiment we are looking at about 280 ETFs and nearly 80,000 examples.
We can see how the error keeps going down consistently until we hit a hard floor, where we cannot learn anymore from these kind of examples. Our model has converged.
Improving the learning process
Now that we have an objective, measurable way to look at model convergence and final mean-errors, we can try different learning algorithms, or learning methods. We can check whether we get better, faster convergence, and lower errors, while leaving all other parameters of the learning process, unchanged.That is: we change the learning method but leave the input data and the input features, intact.
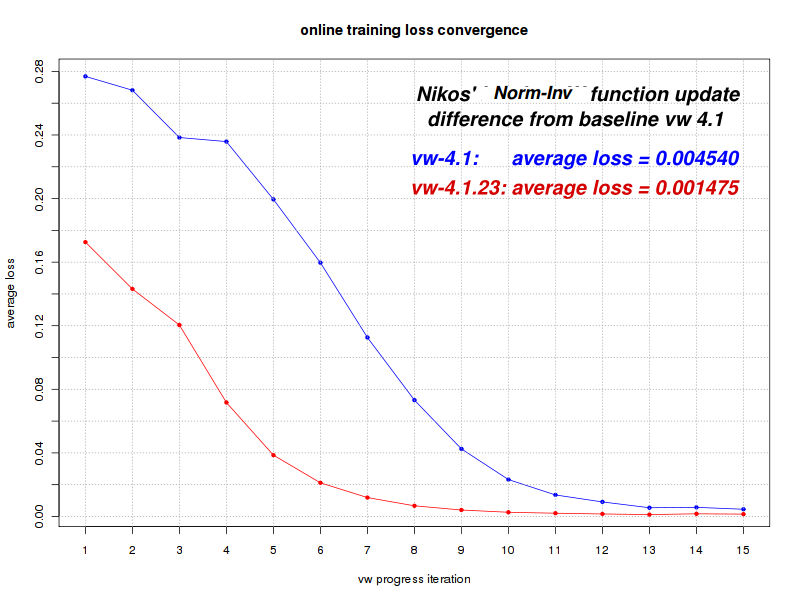
The image above is an example of changing the learning method in a way that dramatically improves the end result. We can see how a new algorithm, which uses norm invariant loss functions (credit and thanks to Nikos Karampatziakis) to update the model feature weights, favorably affects both the convergence speed and the overall mean-error. In this particular example the final mean error is 67.5% smaller than before, indicating that the algorithm labeled 'vw-4.1.23' (red line) is significantly better than the one named 'vw-4.1' (blue line).After seeing such a clear improvement running on the same training-data, I feel confident to switch to the new algorithm.
home faq articles premium contact
The above merely reflects my own thinking and actions at the time of writing. Every investor should make up his own decisions based on his risk tolerance, time-frames, comfort-zones, convictions, and understanding. Never investment advice.
Any feedback is welcome.
-- ariel